


GSMA’s Director of AI Initiatives, Louis Powell, and Vignesh Ethiraj, CTO from NetoAI – a technology partner to the GSMA Open-Telco LLM Benchmarks initiative – explore the critical techniques required to run powerful AI efficiently and effectively at the telecom network edge.
The era of Artificial Intelligence is no longer on the horizon; it’s here, and it’s fundamentally reshaping the telecommunications landscape. Large Language Models (LLMs) are the engine of this transformation, promising to revolutionise everything from customer service to network operations. But raw power isn’t enough. For AI to be truly effective in a telecom environment, it needs to be fast, responsive, and efficient. The key challenge isn’t just what these models can do, but where they do it.
Deploying LLMs at the network edge – closer to where data is generated and actions are taken – is critical for unlocking real-time applications. However, edge devices have inherent constraints on power and computation. This presents a crucial dilemma: how do we run sophisticated AI models in resource-constrained environments without compromising performance?
This blog post is a practical guide for telecom operators and technology leaders. We will dive into the specific techniques, from the model parameters to the inference settings, that can optimise LLM performance for the edge. We’ll also draw a clear line between use cases best suited for the edge and those that belong in a centralised data centre, ensuring you apply the right AI to the right place for maximum impact.
The strategic value of different AI inference options
Not all AI workloads are created equal. The decision of where to run an LLM – at the edge or in a central cloud/data centre hinges on three key factors: latency, data volume, and computational complexity required for the use case.
The use cases can be segmented based on how decentralised the compute requirement is and whether they generally are driven by revenue or cost-saving objectives as shown in the GSMA Intelligence chart below.
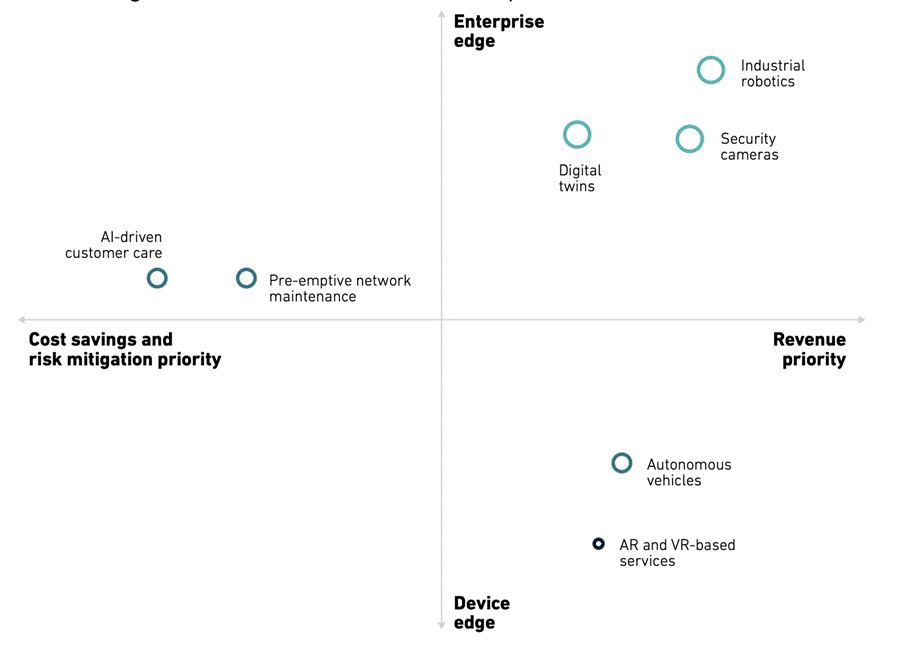
Bubble size based on the perceived importance of the use case by operators.
Source: GSMA Intelligence report: Distributed inference: how AI can turbocharge the edge (March 2025)
AI inference use cases for making money are primarily those that are enterprise-driven, at or near the enterprise edge/on-premises. These include robotics, cameras, digital twins and other IoT applications. The finding chimes with the 5G sales push to enterprise clients that is now well established. Operators see AI as a tool to allow them to expand their enterprise service offering. The use cases shown are top examples from the operator perspective, but the enterprise edge encompasses a broad church of applications, including sports stadia and cashierless points of sale at retail stores, for instance.
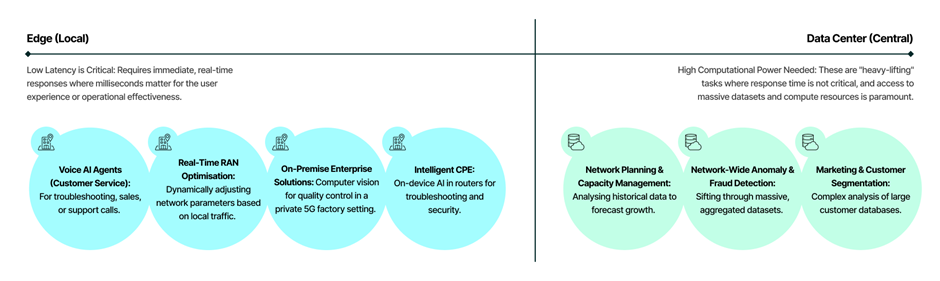
Additional use cases on network and customer management include:
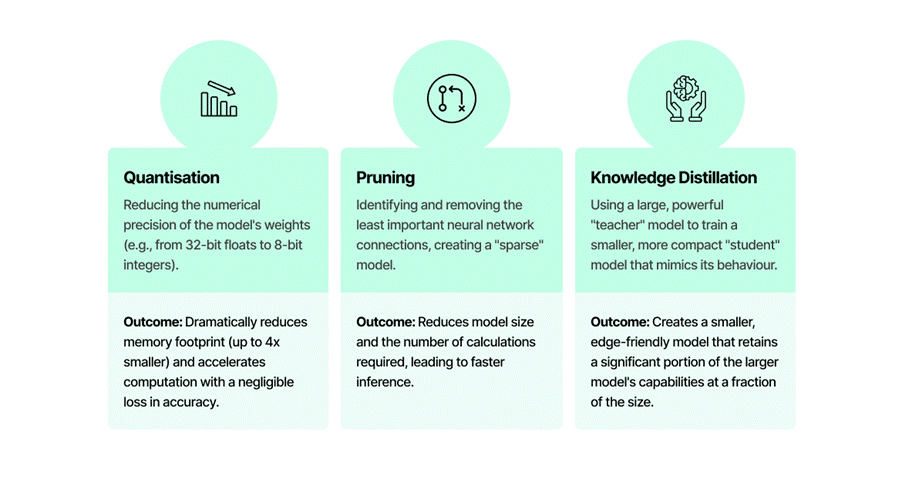
Optimising the Engine: What to Tweak in Your LLM
To get a large model to run efficiently on smaller edge hardware, we need to make it smaller and faster without losing its intelligence. This is achieved through several key techniques, principally quantisation, pruning and knowledge distillation:
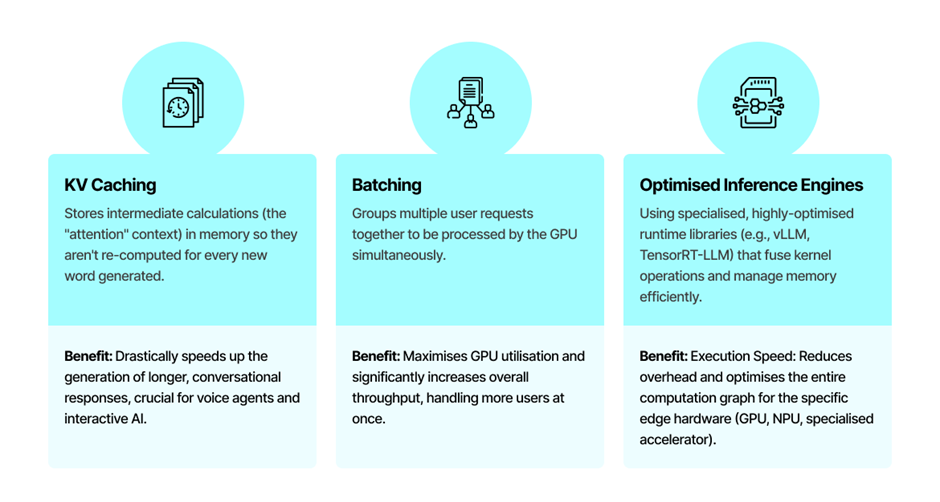
Smart Execution: Tuning Inference Parameters
Once you have an optimised model, you can further boost its performance by changing how you run the inference process.
The Powerhouse: Choosing the Right GPU for the Edge
The telecom edge environment is characterised by space, power, and thermal constraints. Unlike the central data centre which uses high-TDP (Thermal Design Power) cards, the edge requires highly efficient and often compact alternatives.
The market for edge AI is no longer dominated by a single player, allowing operators flexibility based on their existing infrastructure and software ecosystem commitment. The key choices for GPUs fall into two main categories:
A. High-Density/Mid-Range Edge (Micro Data Centres & Aggregation Sites)
These solutions are ideal for the more complex, multi-session LLM use cases like Voice-to-Voice AI Agents and Real-Time Network Triage. They are designed for server environments with modest power budgets.
B. Embedded & Ultra-Low Power Edge (RAN and CPE Devices)
This class addresses the strictest constraints, running highly compressed Small Language Models (SLMs) directly on network equipment or customer devices.
| Vendor | Feature & Benefits (High-Density/Mid-Range Edge) | Feature & Benefits (High-Density/Mid-Range Edge) |
| NVIDIA | RTX A-Series (e.g., A2000, L4) High Performance-per-Watt and low-profile form factor, optimised for INT8/INT4 inference using Tensor Cores. Fits into shallow, high-density edge servers with limited cooling and power. | Jetson AGX Orin / Orin Nano System-on-Module (SOM) offering integrated, high-efficiency GPU and CPU with shared memory. Excellent for deep learning inference. Perfect for integrating AI directly into base stations or ruggedised industrial telecom gateways. |
| AMD | AMD Instinct MI200/MI300 Series (Select SKUs) While high-end, some configurations offer superior memory bandwidth for handling large, multi-session KV Caches. Effective for serving slightly larger, highly-concurrent LLM requests in a modular edge system. | Ryzen AI Processors with XDNA™ NPU Neural Processing Unit (NPU) integrated into the CPU, providing dedicated, ultra-low-power acceleration for smaller models. Enables LLM capabilities on-device (e.g., in CPE or 5G user equipment) without significant power drain. |
| Intel | Data Centre GPU Flex Series Focused on media processing and AI inference density. Optimised for various precisions and offers an open software approach via oneAPI. Provides a flexible alternative for telecom operators standardised on Intel architectures. | Intel Core Ultra with Integrated NPU (e.g., Lunar Lake) Dedicated NPU for persistent, low-power AI workloads and optimised LLM libraries via OpenVINO™. Delivers AI capability to commodity CPE or specialised vRAN (virtualised RAN) compute nodes using a familiar ecosystem. |
| Qualcomm |
| Cloud AI 100 A specialised AI Accelerator designed purely for inference, providing exceptional TOPS/Watt specifically for the data centre and telecom edge environments. Offers a high-efficiency, inference-only option, often used in conjunction with high-density edge servers. |
Building the Intelligent Network of Tomorrow
The integration of LLMs into telecom networks is not a question of if, but how. A blind “cloud-first” approach is not viable for the real-time, data-intensive future our industry is building. Winning requires a nuanced strategy that places AI workloads where they belong.
By embracing model optimisation techniques like quantisation and pruning, fine-tuning inference with methods like KV caching, and selecting the right hardware for the job, operators can overcome the constraints of the edge. This dual approach – running massive, non-urgent tasks in the data centre while deploying lean, efficient models at the edge – will unlock a new generation of services. From seamless customer interactions to a self-optimising, autonomous network, the future of telecommunications is intelligent, and it starts at the edge.
Speak to Louis or Vignesh to share your work and expertise in domain specific AI or to discuss future collaboration. You can also learn more about the application of AI in the telecoms industry through the GSMA AI Use Case Library.